

Tính năng AI Overview của Google đang trở thành tâm điểm bàn tán trên các mạng xã hội khi liên tục đưa ra những đáp án sai sót đối với các câu hỏi đánh vần và đếm ký tự vô cùng cơ bản. Dù có thể lập trình ứng dụng phức tạp trong vài giây hay giải các bài toán chuyên sâu, khả năng ngôn học ở cấp độ chữ cái của các mô hình ngôn ngữ lớn (LLM) đôi khi chỉ tương đương với cấp độ mẫu giáo.
Nhiều người dùng đã chia sẻ ảnh chụp màn hình minh chứng cho sự nhầm lẫn ngớ ngẩn của hệ thống tìm kiếm tích hợp AI này đối với những câu hỏi mà hầu hết học sinh tiểu học đều giải được dễ dàng:
Đếm sai ký tự: Khi được hỏi có bao nhiêu chữ cái "p" trong từ Google, AI Overview khẳng định đáp án là hai.
Bịa đặt chữ cái và viết sai chính tả: Công cụ này tuyên bố từ journalism (báo chí) sở hữu hai chữ "d" và tự ý sửa cách viết của từ này thành journadism.
Biết đúng số lượng nhưng xếp sai vị trí: Với câu hỏi về họ của Tổng thống Mỹ Donald Trump, AI trả lời đúng là có một chữ "p", nhưng thành phẩm chữ viết đầu ra lại bị biến dạng thành Trpum.
Phía đại diện Google đã phải lên tiếng thừa nhận rằng việc đếm ký tự trong phạm vi từ ngữ là một thách thức kỹ thuật đã được ghi nhận đối với các cấu trúc LLM và hãng đang nỗ lực tìm kiếm giải pháp khắc phục vấn đề này.
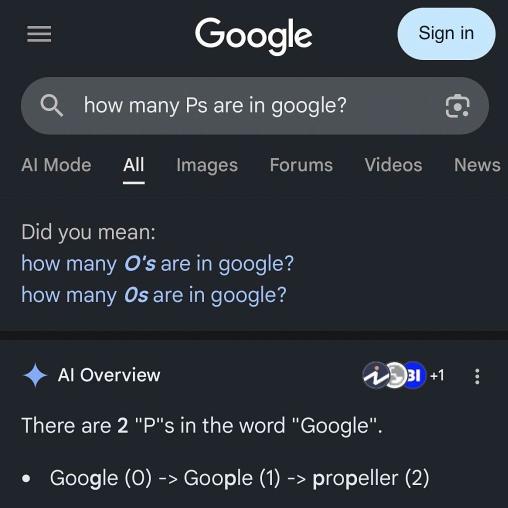
AI Overview trả lời có hai chữ cái "p" trong từ Google. Ảnh: X/mersomas
Theo các chuyên gia và nhà nghiên cứu công nghệ, các mô hình ngôn ngữ lớn vốn không được xây dựng để thấu hiểu cách đánh vần.
Cơ chế hoạt động của Transformer: Các hệ thống LLM xây dựng trên nền tảng kiến trúc transformer không tiếp cận câu văn theo từng chữ cái riêng lẻ. Thay vào đó, chúng phân tách văn bản thành những đơn vị dữ liệu gọi là token (có thể là một từ hoàn chỉnh, một âm tiết hoặc một chữ cái tùy mô hình).
Biểu diễn số học thay vì đọc hiểu: Thay vì "đọc" như con người, AI chuyển đổi văn bản thành các chuỗi biểu diễn số học, sau đó đặt chúng vào ngữ cảnh để tính toán xác suất phản hồi hợp lý.
Hạn chế nhận diện cấu trúc: Phó giáo sư Matthew Guzdial từ Đại học Alberta giải thích: Khi người dùng nhập câu lệnh, từ ngữ sẽ dịch thành dạng mã hóa. Khi thấy từ "the", LLM biết ý nghĩa của "the" dưới dạng mã hóa, nhưng bản thân nó hoàn toàn không biết từ đó được cấu thành từ ba chữ cái riêng lẻ t-h-e.
Chính mô hình Gemini của Google cũng tự đưa ra lời giải thích tương tự khi được chất vấn về lỗi chính tả:
"Tôi không nhìn hay viết văn bản theo cách bạn làm. Khi viết từ 'apple' (quả táo), não bạn xử lý 5 chữ cái riêng biệt. Nhưng tôi xem từ đó như một đơn vị duy nhất gọi là token (biểu diễn số học của toàn bộ hoặc một phần từ). Tôi xử lý từ ngữ như một khối nghĩa hoàn chỉnh thay vì chuỗi chữ cái riêng lẻ, nên không 'đánh vần' các từ theo trình tự."
Gemini khẳng định mình biết chính xác từ "apple" nghĩa là gì và liên hệ ra sao với các từ khác, nhưng nó sẽ không tập trung vào việc đánh vần trừ khi được yêu cầu cụ thể.

Logo Google theo cách đánh vần sai của AI Overview. Ảnh: Google/TechCrunch
Hạn chế về mặt chính tả này diễn ra phổ biến ở nhiều mô hình AI hiện nay chứ không độc quyền ở riêng hệ sinh thái của Google. Tuy nhiên, các mô hình này chỉ đôi khi "đánh vần kém" ngẫu nhiên ở một số tình huống chứ không phải lúc nào cũng mắc lỗi.
Giới chuyên gia phân tích đánh giá vấn đề này không quá cấp bách đối với giới nghiên cứu và khó có thể giải quyết triệt để trong tương lai gần. Lý do là bởi giá trị cốt lõi và lợi ích lớn nhất của LLM nằm ở khả năng lập trình, tư duy và giải quyết các bài toán phức tạp chứ không nằm ở khả năng đánh vần. Nghiên cứu sinh tiến sĩ Sheridan Feucht tại Đại học Northeastern nhận định, việc đạt được một bộ từ vựng token hoàn hảo để định nghĩa "từ ngữ" cho mô hình ngôn ngữ là một bài toán vô cùng rối loạn và phức tạp.
Dù vậy, đây vẫn là một lời nhắc nhở thực tế cho người dùng toàn cầu: Trí tuệ nhân tạo dù thông minh đến đâu vẫn không hoàn hảo. Thay vì tin tưởng một cách tuyệt đối vào kết quả đầu ra, chúng ta luôn cần có tư duy phản biện, chủ động kiểm tra và thẩm định lại độ chính xác của dữ liệu.